In my previous post, I shared how Generative AI (GenAI) is transforming the way we approach observability as we unlock new possibilities for automation. From there, we concluded that Large Language Models (LLMs) are great at identifying patterns, generating boilerplates, and summarizing data.
However, without the right context, they will just be blindly guessing answers, making them unreliable. Hence, we arrive at a new problem statement:
In a scenario where LLMs have access to data from multiple independent sources to answer a given prompt, how do they decide and collect from the correct sources in an efficient, consistent and reliable manner?
In this article, we will explore the Model Context Protocol (MCP) to understand how it serves as a bridge between LLMs and external data sources in the context of observability.
What is MCP?
According to the official documentation, the Model Context Protocol (MCP) is an open standard that defines how applications provide context to LLMs.
At a high level, the architecture consists of three key components:
-
MCP Host - LLM/Application.
-
MCP Client - Connects the MCP hosts with MCP servers via the MCP protocol.
-
MCP Server - A lightweight program that defines tools that can interact with datasources and remote services.
MCP Host + MCP Client ───> MCP Server A ───> Datasource A
└────> Datasource B
└────> MCP Server B ───> Remote Service A
└────> Remote Service B
... ...Each MCP server can be treated as a toolbox. When an LLM is given access to one or more MCP servers, it gains access to each set of tools, each tool representing a function that can perform CRUD operations to a datasource or API.
Because all interactions go through the MCP protocol, data is returned in a clean, predictable, and standardized format to the LLMs.
How do LLMs decide which tools to use?
When we ask a question to an MCP host, the following steps are performed:
-
The LLM is configured with a MCP client to interact with one or more MCP servers.
-
From the list of available tools, the LLM will use its in-built natural language reasoning to analyse and determine which tool to use and suggest suitable input parameters. For each tool, the MCP client will attempt a request with the suggested parameters to the MCP server.
-
The MCP server will execute the tools if the input tool parameters are of the correct format.
-
The tool results are sent back to the MCP client via Server-Sent Events (SSE). The MCP client will use the results as additional context, combining it with the question. This combined data is then sent to the LLM for further processing.
-
Depending on the subsequent response generated, steps 2-4 might be performed again to retrieve more context.
-
Once all possible tools are exhausted, the LLM will return a final response back to the user.
The above workflow is explained in greater detail in this article.
Benefits of using MCP
1. Standardization of tools
We define each tool once and reuse it across any LLM. This significantly reduces the development time and complexity when building AI applications and workflows that require interacting with multiple independent datasources.
2. Plug-and-play flexibilty
Each MCP server functions as a plugin which can be easily added, removed, replaced and scaled independently.
3. Built-in security best practices
This framework also extends several best practices like (Lifecycle Management, Authorization, etc.) to ensure that interactions with highly sensitive datasources and remote services are handled in a consistent and secure manner.
Characteristics of observability data
According to an article published by groundcover, observability data can be challenging for LLMs to consume because of the following characteristics:
-
High Volumes
For a typical organization, Terabytes (TB) logs and metrics are being ingested daily. As LLMs operate wtih limited context windows, processing data in this order of magnitude is impractical.
-
High Cost
Likewise, since LLMs charge by token usage, feeding LLMs with large amount of unstructured logs and metrics can be very expensive.
-
Spikey and Unpredicatable
Observability data tends to behave in a bursty manner — quiet during normal operation, then rapidly spiking during incidents. Due to this unpredictability, it is difficult to pre-plan on which data should be prioritised for LLMs.
From the above characteristics, we can observe that it is not practical to shove raw and unfiltered metrics and logs to LLMs.
The more pragmatic approach is to provide this data in a distilled and structured format for LLMs to process them more effectively, which is easier to implement today using MCP.
Problem Statement: Building a MCP server for observability
Let's deep dive on how we can implement the MCP framework for observabilty.
The objective is to implement an end-to-end LLM workflow that is able to rationalise data from different observability datasources to achieve the following functions:
-
Summarize alerts and incidents.
-
Perform RCA by correlating incidents, alerts, metrics, and logs.
-
Recommend actionable solutions post-investigation.
Background
For this project, we will be setting the following background. We expect the LLM to capture this backstory during our testing.
Three applications (gateway, notifications and payments) are
deployed in production.
Out of these, gateway and payments apps
are showing signs of degradation.Datasource definitions
On a high level, observability datasources can be divided into several forms (logs, alerts, incidents, metrics, events).
In production, we will be expected to write API calls as the data will be stored in remote services. Hence, for simplicity, we define each datasource in our local filesystem, stored in a folder: datasources.
/datasources
/logs
/gateway.log
/notifications.log
/payments.log
/alerts.json
/incidents.json
/metrics.json
/events.jsonExamples
-
gateway.log2025-07-06 10:02:45 WARNING Disk usage at 85% 2025-07-06 10:03:50 ERROR Failed to forward request to backend 2025-07-06 10:05:00 INFO Recovered from transient error 2025-07-06 10:06:15 INFO Monitoring disk usage closely 2025-07-06 10:07:30 WARNING Disk usage at 87% ... -
alerts.json{ "alert_id": "alert_001", "application": "payments", "severity": "critical", "timestamp": "2025-07-06T10:07:15Z", "message": "Database connection refused", "action_required": true, "acknowledged": false }, ... -
incidents.json{ "incidentName": "gateway-resource-warnings", "application": "gateway", "description": "Warnings about disk usage and authentication failures", "alerts": [ { "alert_id": "alert_002", "severity": "warning", "timestamp": "2025-07-06T10:02:45Z", "message": "High disk usage nearing capacity", "action_required": false, "acknowledged": true }, { "alert_id": "alert_004", "severity": "warning", "timestamp": "2025-07-06T10:09:00Z", "message": "Temporary failure in authentication service", "action_required": false, "acknowledged": true } ], "summary": "Grouped warnings on resource utilization and auth service issues on Gateway.", "resolved": false }, ... -
metrics.json{ "application": "notifications", "data": [ { "timestamp": "2025-07-06T10:00:00Z", "error_count": 0, "warning_count": 0, "email_sent": 0, "sms_sent": 0, "webhook_processed": 0 }, { "timestamp": "2025-07-06T10:01:10Z", "error_count": 0, "warning_count": 0, "email_sent": 20, "sms_sent": 50, "webhook_processed": 10 }, ... ] }, ... -
events.json... { "timestamp": "2025-07-06T10:11:00Z", "application": "payments", "name": "circuit_breaker_active" }, ...
Tool definitions
Let's now create a server.py file to define our tool definitions, using the Python MCP SDK.
get_info_logs- Get INFO logsget_error_logs- Get ERROR logsget_warning_alerts- Get warning alertsget_error_alerts- Get error alertsget_unresolved_incidents- Get unresolved incidentsget_resolved_incidents- Get resolved incidentsget_metrics- Get list of metricsget_events- Get list of events
Implementation
from mcp.server.fastmcp import FastMCP
import json
from enum import Enum
from pathlib import Path
cwd = Path(__file__).parent.resolve()
mcp = FastMCP(name="mcp_observability_server")
# ENUMs
class AppName(str, Enum):
GATEWAY = "gateway"
NOTIFICATIONS = "notifications"
PAYMENTS = "payments"
# Datasource paths
DATASOURCE_PATH = cwd / "datasources"
LOGS_FOLDER = DATASOURCE_PATH / "logs"
LOGS = {
"gateway": DATASOURCE_PATH / "logs/gateway.log",
"notifications": DATASOURCE_PATH / "logs/notifications.log",
"payments": DATASOURCE_PATH / "logs/payments.log",
}
ALERTS = DATASOURCE_PATH / "alerts.json"
INCIDENTS = DATASOURCE_PATH / "incidents.json"
METRICS = DATASOURCE_PATH / "metrics.json"
EVENTS = DATASOURCE_PATH / "events.json"
# LOGS
@mcp.tool(name="get_info_logs", description="get info logs")
def get_info_logs(appName: AppName | None = None):
result = []
if appName:
appName = appName.value.lower()
with open(file=LOGS[appName], mode="r") as log_file:
lines = log_file.readlines()
for line in lines:
if "info" in line.lower():
result.append(line)
return result
for log in LOGS:
with open(file=log, mode="r") as log_file:
lines = log_file.readlines()
for line in lines:
if appName and appName.value.lower() not in log.lower():
continue
if "info" in line.lower():
result.append(line)
return result
@mcp.tool(name="get_error_logs", description="get error logs")
def get_error_logs(appName: AppName | None = None):
result = []
if appName:
appName = appName.value.lower()
with open(file=LOGS[appName], mode="r") as log_file:
lines = log_file.readlines()
for line in lines:
if "error" in line.lower():
result.append(line)
return result
for log in LOGS:
with open(file=log, mode="r") as log_file:
lines = log_file.readlines()
for line in lines:
if "error" in line.lower():
result.append(line)
return result
# ALERTS
@mcp.tool(name="get_warning_alerts", description="get warning alerts")
def get_warning_alerts(appName: AppName | None = None):
result = []
with open(file=ALERTS, mode="r") as alert_file:
alerts = json.load(alert_file)
for alert in alerts:
if appName and alert["application"].lower() != appName.value.lower():
continue
if alert["severity"].lower() == "warning":
result.append(alert)
return result
@mcp.tool(name="get_critical_alerts", description="get critical alerts")
def get_critical_alerts(appName: AppName | None = None):
result = []
with open(file=ALERTS, mode="r") as alert_file:
alerts = json.load(alert_file)
for alert in alerts:
if appName and alert["application"].lower() != appName.value.lower():
continue
if alert["severity"].lower() == "critical":
result.append(alert)
return result
# INCIDENTS
@mcp.tool(name="get_unresolved_incidents", description="get unresolved incidents")
def get_unresolved_incidents(appName: AppName | None = None):
with open(file=INCIDENTS, mode="r") as incident_file:
incidents = json.load(incident_file)
result = []
for incident in incidents:
if appName and incident["application"].lower() != appName.value.lower():
continue
if incident["resolved"] == False:
result.append(incident)
return result
@mcp.tool(name="get_resolved_incidents", description="get resolved incidents")
def get_resolved_incidents(appName: AppName | None = None):
with open(file=INCIDENTS, mode="r") as incident_file:
incidents = json.load(incident_file)
result = []
for incident in incidents:
if appName and incident["application"].lower() != appName.value.lower():
continue
if incident["resolved"]:
result.append(incident)
return result
# METRICS
@mcp.tool(name="get_metrics", description="get metrics")
def get_metrics(appName: AppName | None = None):
with open(file=METRICS, mode="r") as metrics_file:
metrics = json.load(metrics_file)
result = []
for metric in metrics:
if appName and metric["application"].lower() != appName.value.lower():
continue
result.append(metric)
return result
# EVENTS
@mcp.tool(name="get_events", description="get events")
def get_events(appName: AppName | None = None):
with open(file=EVENTS, mode="r") as event_file:
events = json.load(event_file)
result = []
for event in events:
if appName and event["application"].lower() != appName.value.lower():
continue
result.append(event)
return result
if __name__ == "__main__":
mcp.run(transport='stdio')Testing using Github Copilot
To validate if these tools are working, we can test using a MCP host (Github Copilot, Claude, etc.) integrated with this MCP server.
For my testing, I have followed these steps to configure VSCode's settings.json to instruct Github Copilot to interact with the MCP server locally.
-
settings.json*... // Add this to the configuration "mcp": { "servers": { "my-mcp-server-XXXXX": { "type": "stdio", "command": "<path to server file>/venv/bin/<python executable>", "args": [ "<path to server file>/server.py" ] } } } ...*For newer versions of VSCode, mcp server configurations for Github Copilot are managed in
.vscode/mcp.jsoninstead ofsettings.json. -
Prompt Example
We can now test the tools by providing a prompt. For this case, I have asked Copilot:
What's wrong with the gateway application?On identifying relevant tools to answer this prompt, Copilot will suggest appropriate input parameters and ask for permission to run them. This indicates a successful integration with the MCP server.
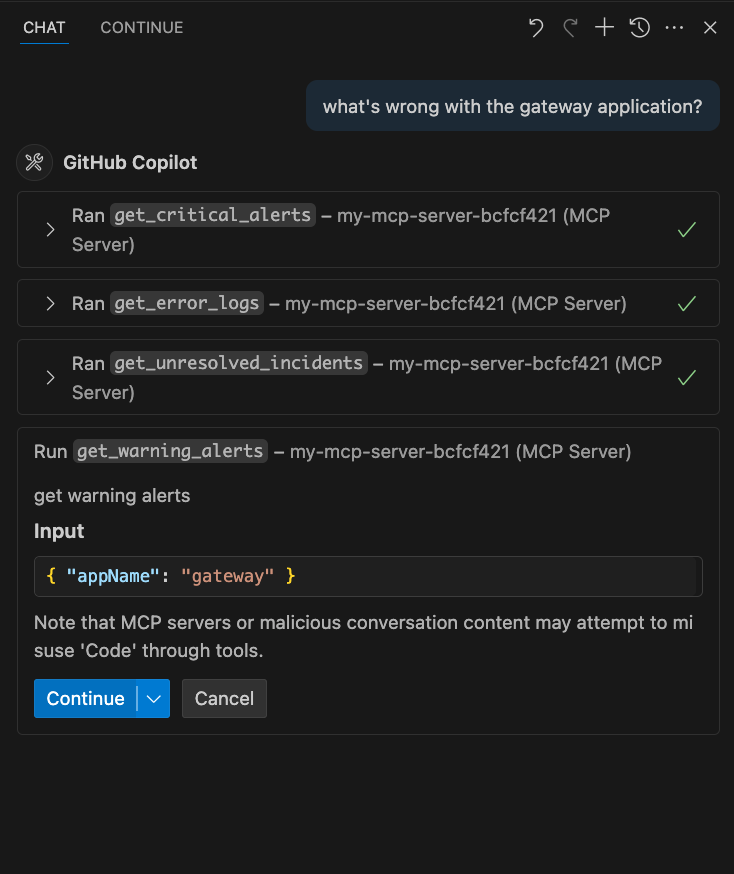
-
Final Result
After trying all possible tools in multiple iterations, it will end off with an output that captures all the relevant context it has gathered from the tools.
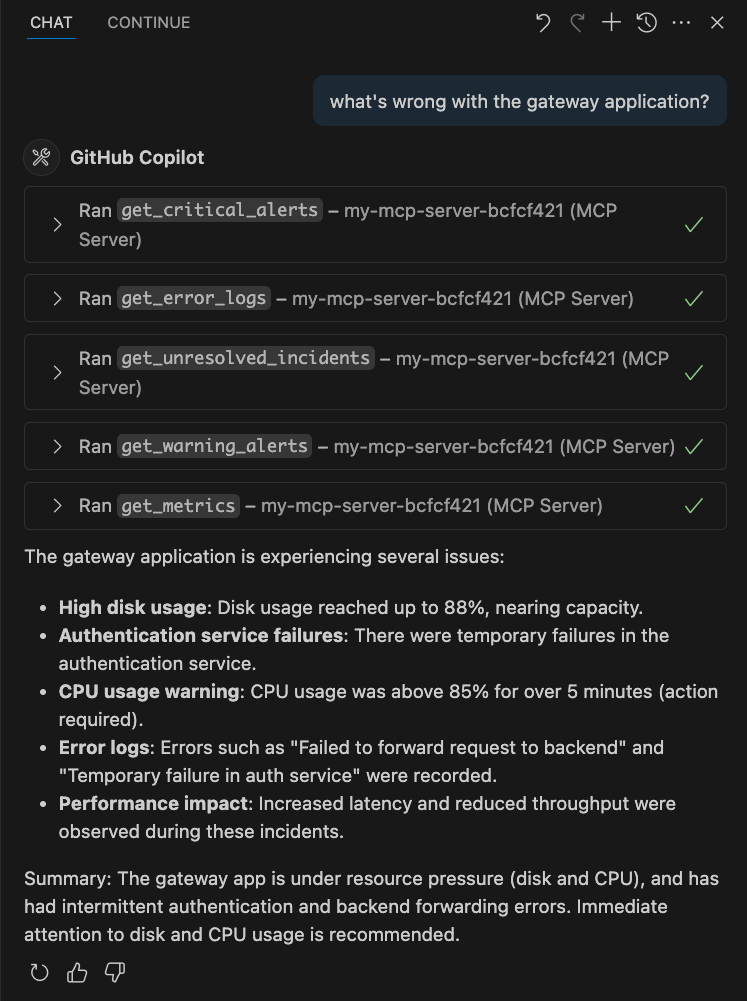
From this working example, Github Copilot was able to intelligently decipher which tool to use despite the limited context. We managed to transition from specifying our requirements as a user to automating the collection of contextual data using MCP servers.
In addition, the process is also iterative - after using a tool to fetch some data, the LLM might consider running the tool again or try other tools to gather more context until it has exhausted all tools or concluded that there is sufficient context to answer the prompt.
This mimics the way humans think when they conduct research - revisiting the same documentation, gathering data from multiple places, and lastly summarising the collected references.
This new AI paradigm enables developers to easily create more complex workflows in LLMs, unlocking more intelligent use-cases like:
-
Automating RCAs in real-time
-
Suggesting and taking action on incident remediation strategies
-
Continuous config monitoring and taking action on syntax errors or harmful side effects from bad infrastructure configs
Source code
If you would like to explore and learn how you can run this MCP server locally, feel free to check out this repo.
Future work
As of now, this is just a simple POC. There are still other areas that every team should consider before rolling it out for production.
-
Structuring your codebase for maintainability
-
Using a Proxy Server as an intermediary between clients and underlying MCP servers
-
Caching commonly served data from tools
Final words
From this article, we can conclude that the Model Context Protocol (MCP) is a powerful and reliable framework for standardizing interactions between external services and LLMs.
By providing structured and consistent access to data, MCP makes it significantly easier to build intelligent agents and complex AI workflows. This is a huge advantage for observability, we can unlock greater productivity with new use-cases like automated RCA, proactive incident remediation, and continuous monitoring.
Stay tuned for more!